Dimension reduction of multivariate count data with PLN-PCA
PLN team
2026-07-09
Source:vignettes/PLNPCA.Rmd
PLNPCA.RmdPreliminaries
This vignette illustrates the standard use of the PLNPCA
function and the methods accompanying the R6 Classes
PLNPCAfamily and PLNPCAfit.
Requirements
The packages required for the analysis are PLNmodels plus some others for data manipulation and representation:
The main function PLNPCA relies on
parallel::mclapply to perform parallel computing: set the
number of workers with the mc.cores option (forking-based,
so only effective on Unix-like systems; ignored on Windows):
options(mc.cores = 2)Data set
We illustrate our point with the trichoptera data set, a full description of which can be found in the corresponding vignette. Data preparation is also detailed in the specific vignette.
data(trichoptera)
trichoptera <- prepare_data(trichoptera$Abundance, trichoptera$Covariate)The trichoptera data frame stores a matrix of counts
(trichoptera$Abundance), a matrix of offsets
(trichoptera$Offset) and some vectors of covariates
(trichoptera$Wind, trichoptera$Temperature,
etc.)
Mathematical background
In the vein of Tipping and Bishop (1999), we introduce in Chiquet et al. (2018) a probabilistic PCA model for multivariate count data which is a variant of the Poisson Lognormal model of Aitchison and Ho (1989) (see the PLN vignette as a reminder). Indeed, it can be viewed as a PLN model with an additional rank constraint on the covariance matrix such that .
This PLN-PCA model can be written in a hierarchical framework where a sample of -dimensional observation vectors is related to some -dimensional vectors of latent variables as follows:
The parameter corresponds to the main effects, the matrix to the loadings in the parameter spaces and to the scores of the -th observation in the low-dimensional latent subspace of the parameter space. The dimension of the latent space corresponds to the number of axes in the PCA or, in other words, to the rank of . An hopefully more intuitive way of writing this model is the following: where the interpretation of PLN-PCA as a rank-constrained PLN model is more obvious.
Covariates and offsets
Just like PLN, PLN-PCA generalizes to a formulation close to a multivariate generalized linear model where the main effect is due to a linear combination of covariates and to a vector of offsets in sample . The latent layer then reads where is a matrix of regression parameters.
Optimization by Variational inference
Dimension reduction and visualization is the main objective in (PLN)-PCA. To reach this goal, we need to first estimate the model parameters. Inference in PLN-PCA focuses on the regression parameters and on the covariance matrix . Technically speaking, we adopt a variational strategy to approximate the log-likelihood function and optimize the consecutive variational surrogate of the log-likelihood with a gradient-ascent-based approach. To this end, we rely on the CCSA algorithm of Svanberg (2002) implemented in the C++ library (Johnson 2011), which we link to the package. Technical details can be found in Chiquet et al. (2018).
Analysis of trichoptera data with a PLNPCA model
In the package, the PLNPCA model is adjusted with the function
PLNPCA, which we review in this section. This function
adjusts the model for a series of value of
and provides a collection of objects PLNPCAfit stored in an
object with class PLNPCAfamily.
The class PLNPCAfit inherits from the class
PLNfit, so we strongly recommend the reader to be
comfortable with PLN and PLNfit before using
PLNPCA (see the PLN vignette).
A model with latent main effects for the Trichoptera data set
Adjusting a collection of fits
We fit a collection of models as follows:
##
## Initialization...
##
## Adjusting 4 PLN models for PCA analysis.
## Rank approximation = 1 Rank approximation = 2 Rank approximation = 3 Rank approximation = 4
## Post-treatments
## DONE!Note the use of the formula object to specify the model,
similar to the one used in the function PLN.
Structure of PLNPCAfamily
The PCA_models variable is an R6 object
with class PLNPCAfamily, which comes with a couple of
methods. The most basic is the show/print method, which
sends a brief summary of the estimation process:
PCA_models## --------------------------------------------------------
## COLLECTION OF 4 POISSON LOGNORMAL MODELS
## --------------------------------------------------------
## Task: Principal Component Analysis
## ========================================================
## - Ranks considered: from 1 to 4
## - Best model (greater BIC): rank = 4
## - Best model (greater ICL): rank = 3One can also easily access the successive values of the criteria in the collection
| param | nb_param | loglik | BIC | AIC | ICL |
|---|---|---|---|---|---|
| 1 | 34 | -1042.0394 | -1108.2004 | -1076.0394 | -1120.5893 |
| 2 | 50 | -731.6823 | -828.9778 | -781.6823 | -860.3102 |
| 3 | 65 | -640.3650 | -766.8492 | -705.3650 | -825.0339 |
| 4 | 79 | -599.6222 | -753.3491 | -678.6222 | -844.7847 |
A quick diagnostic of the optimization process is available via the
convergence field:
| param | nb_param | status | backend | objective | iterations | |
|---|---|---|---|---|---|---|
| out | 1 | 34 | 3 | nlopt | -36014.27 | 606 |
| elt | 2 | 50 | 3 | nlopt | -36324.63 | 1536 |
| elt.1 | 3 | 65 | 3 | nlopt | -36415.95 | 947 |
| elt.2 | 4 | 79 | 3 | nlopt | -36456.69 | 1226 |
Comprehensive information about PLNPCAfamily is
available via ?PLNPCAfamily.
Model selection of rank
The plot method of PLNPCAfamily displays
evolution of the criteria mentioned above, and is a good starting point
for model selection:
plot(PCA_models)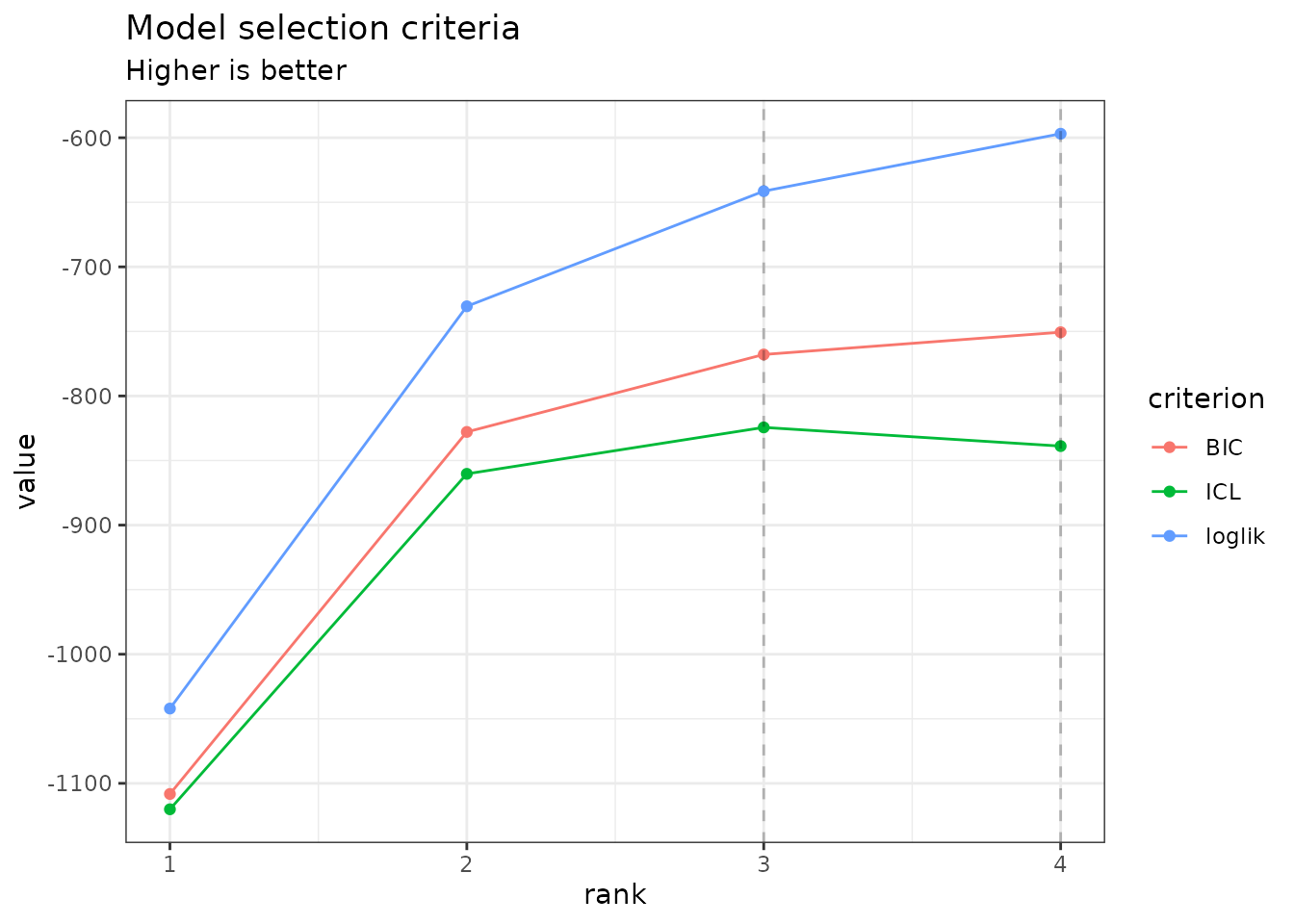
Note that we use the original definition of the BIC/ICL criterion
(),
which is on the same scale as the log-likelihood. A popular
alternative consists in using
instead. You can do so by specifying reverse = TRUE:
plot(PCA_models, reverse = TRUE)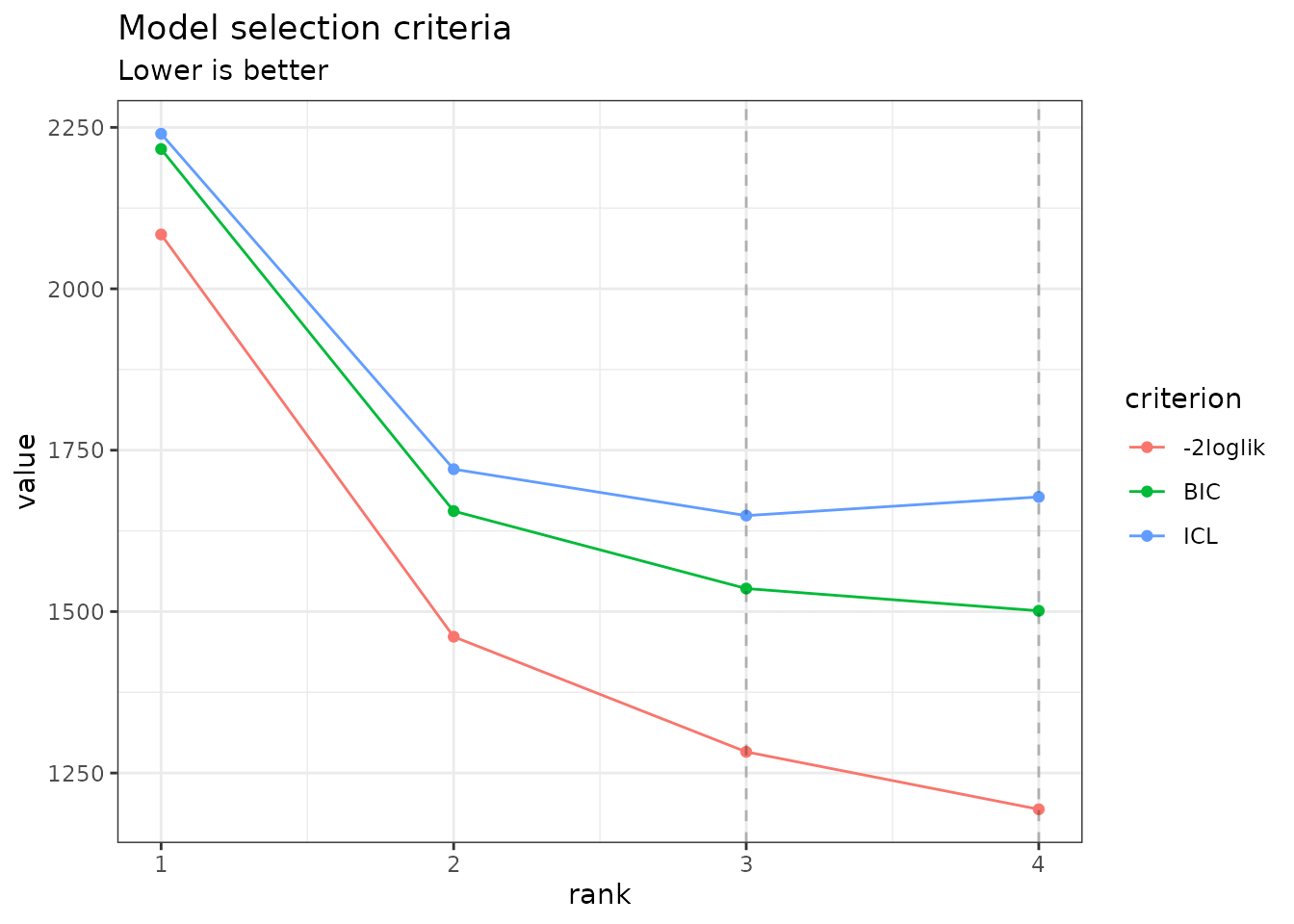
In this case, the variational lower bound of the log-likelihood is
hopefully strictly increasing (or rather decreasing if using
reverse = TRUE) with the number of axes (or subspace
dimension). Also note the (approximated)
which is displayed for each value of
(see (Chiquet et al.
2018) for details on its computation).
From this plot, we can see that the best model in terms of BIC or ICL
is obtained for a rank
or
.
We may extract the corresponding model with the method
getBestModel("ICL"). A model with a specific rank can be
extracted with the getModel() method:
myPCA_ICL <- getBestModel(PCA_models, "ICL")
myPCA_BIC <- getModel(PCA_models, 3) # getBestModel(PCA_models, "BIC") is equivalent here Structure of PLNPCAfit
Objects myPCA_ICL and myPCA_BIC are
R6Class objects of class PLNPCAfit which in
turns own a couple of methods, some inherited from PLNfit
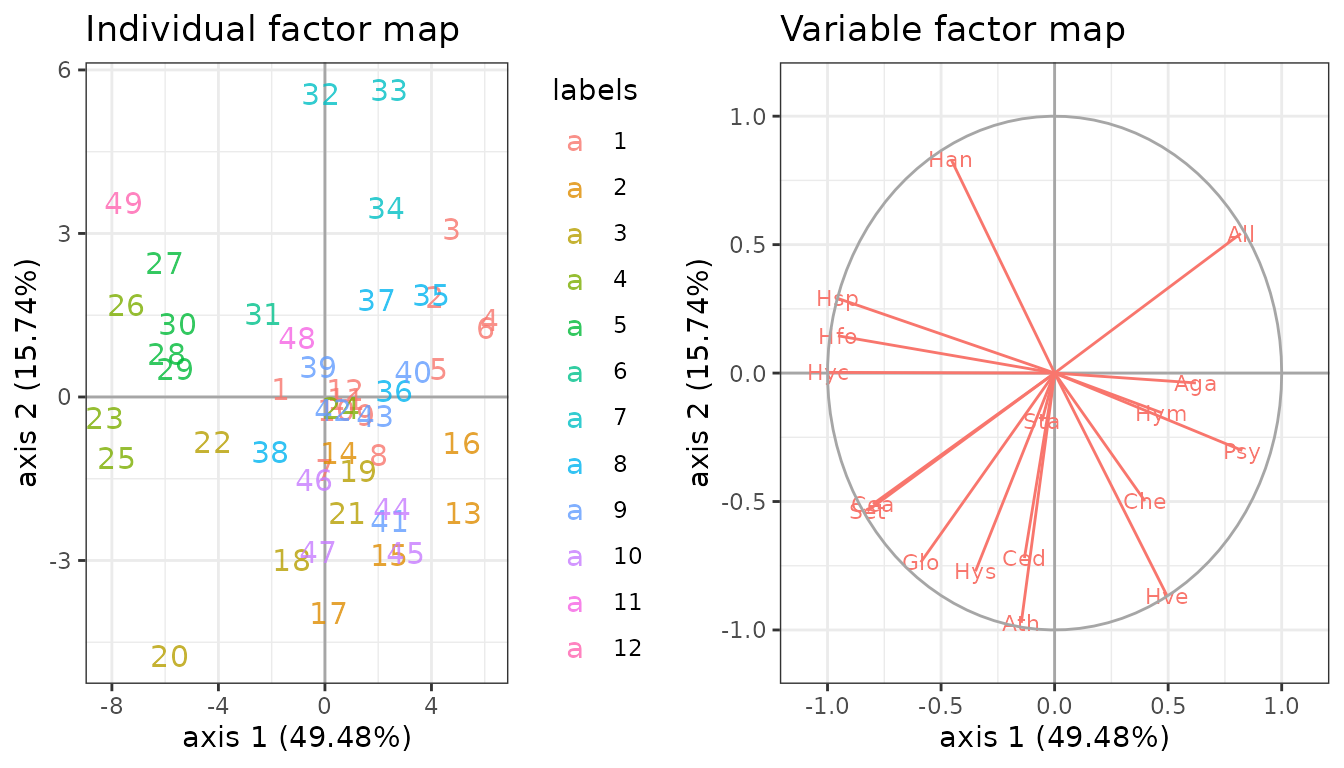
and some others specific, mostly for visualization purposes. The
plot method provides individual maps and correlation
circles as in usual PCA. If an additional classification exists for the
observations – which is the case here with the available classification
of the trapping nights – , it can be passed as an argument to the
function.1
plot(myPCA_ICL, ind_cols = trichoptera$Group)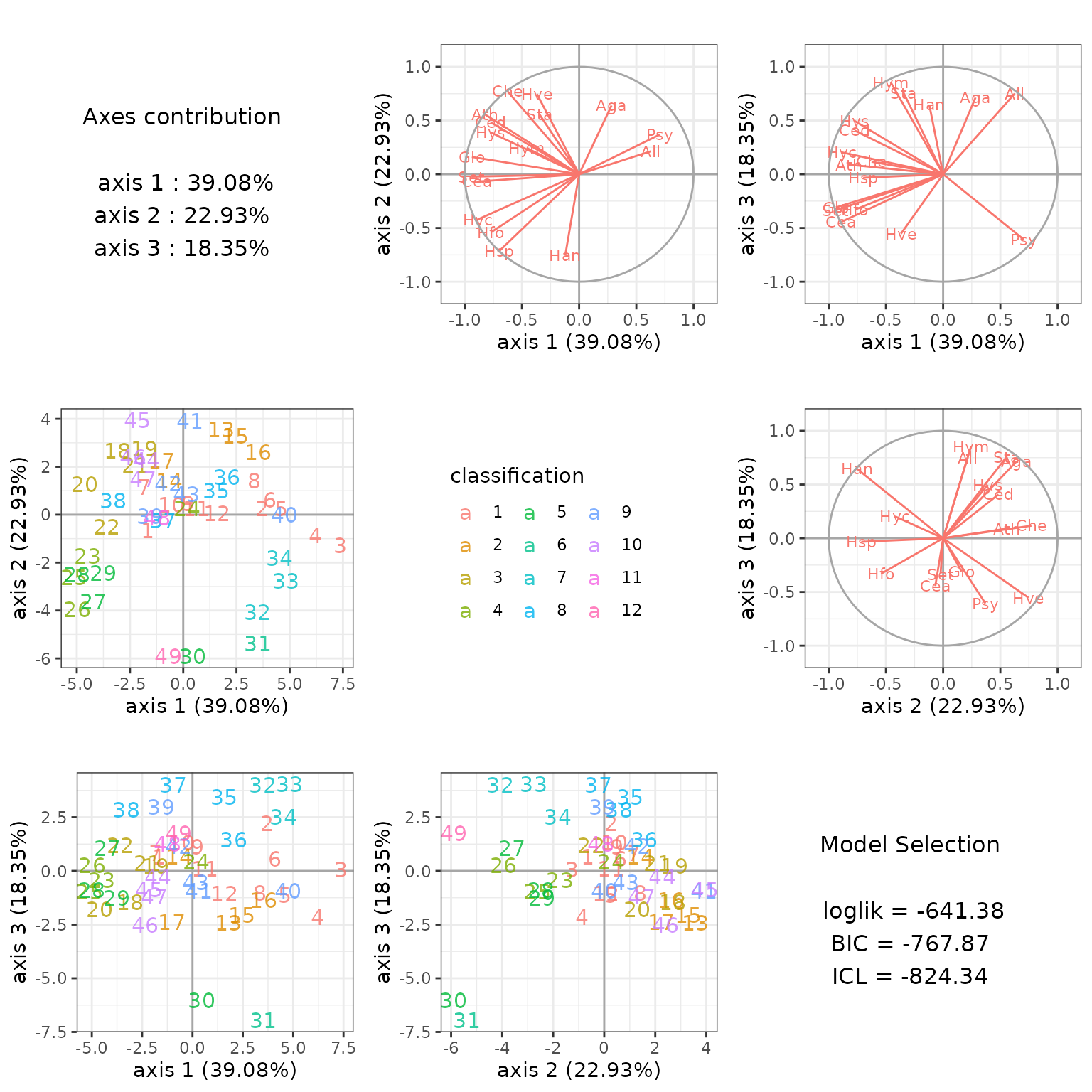
Among other fields and methods (see ?PLNPCAfit for a
comprehensive view), the most interesting for the end-user in the
context of PCA are
- the regression coefficient matrix
| Che | Hyc | Hym | Hys | Psy | Aga | Glo | Ath | Cea | Ced | Set | All | Han | Hfo | Hsp | Hve | Sta | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| (Intercept) | -7.434211 | -8.057369 | -3.018784 | -6.87061 | -0.5366141 | -3.834332 | -6.38331 | -5.804006 | -7.311393 | -3.513852 | -4.084953 | -5.04075 | -4.33353 | -5.937828 | -3.951039 | -7.146032 | -2.58505 |
- the estimated covariance matrix with fixed rank
- the rotation matrix (in the latent space)
| PC1 | PC2 | PC3 | |
|---|---|---|---|
| Che | -0.2029934 | 0.3248846 | -0.0291819 |
| Hyc | -0.4328807 | -0.2257067 | 0.2086481 |
| Hym | -0.1300347 | 0.1694486 | 0.2947345 |
| Hys | -0.4318781 | 0.3662567 | 0.2759175 |
| Psy | 0.0511372 | 0.0172489 | -0.0713042 |
| Aga | 0.0679111 | 0.2914636 | 0.1976951 |
- the principal components values (or scores)
| PC1 | PC2 | PC3 |
|---|---|---|
| -1.752095 | -0.4456495 | 0.7081145 |
| 3.487919 | 0.9677894 | 2.0298173 |
| 7.319281 | -1.1679131 | 0.5483579 |
| 6.335651 | -1.4185459 | -1.6658207 |
| 4.628082 | -0.0531473 | -1.0153053 |
| 3.983035 | 0.7969679 | 0.4444038 |
PLNPCAfit also inherits from the methods of
PLNfit (see the appropriate
vignette). Most are recalled via the show method:
myPCA_ICL## Poisson Lognormal with rank constrained for PCA (rank = 3)
## ==================================================================
## nb_param loglik BIC AIC ICL
## 65 -640.365 -766.849 -705.365 -825.034
## ==================================================================
## * Useful fields
## $model_par, $latent, $latent_pos, $var_par, $optim_par
## $loglik, $BIC, $ICL, $loglik_vec, $nb_param, $criteria
## * Useful S3 methods
## print(), coef(), sigma(), vcov(), fitted()
## predict(), predict_cond(), standard_error()
## * Additional fields for PCA
## $percent_var, $corr_circle, $scores, $rotation, $eig, $var, $ind
## * Additional S3 methods for PCA
## plot.PLNPCAfit()Additional visualization
We provide simple plotting functions but a wealth of plotting
utilities are available for factorial analyses results. The following
bindings allow you to use widely popular tools to make your own plots:
$eig, $var and $ind.
## All summaries associated to the individuals
str(myPCA_ICL$ind)## List of 4
## $ coord : num [1:49, 1:3] -1.75 3.49 7.32 6.34 4.63 ...
## ..- attr(*, "dimnames")=List of 2
## .. ..$ : chr [1:49] "1" "2" "3" "4" ...
## .. ..$ : chr [1:3] "Dim.1" "Dim.2" "Dim.3"
## $ cos2 : num [1:49, 1:3] 0.814 0.706 0.97 0.893 0.954 ...
## ..- attr(*, "dimnames")=List of 2
## .. ..$ : chr [1:49] "1" "2" "3" "4" ...
## .. ..$ : chr [1:3] "Dim.1" "Dim.2" "Dim.3"
## $ contrib: num [1:49, 1:3] 0.621 2.463 10.845 8.126 4.336 ...
## ..- attr(*, "dimnames")=List of 2
## .. ..$ : chr [1:49] "1" "2" "3" "4" ...
## .. ..$ : chr [1:3] "Dim.1" "Dim.2" "Dim.3"
## $ dist : Named num [1:49] 1.94 4.15 7.43 6.7 4.74 ...
## ..- attr(*, "names")= chr [1:49] "1" "2" "3" "4" ...
## Coordinates of the individuals in the principal plane
head(myPCA_ICL$ind$coord)## Dim.1 Dim.2 Dim.3
## 1 -1.752095 -0.44564951 0.7081145
## 2 3.487918 0.96778936 2.0298173
## 3 7.319281 -1.16791306 0.5483579
## 4 6.335651 -1.41854591 -1.6658207
## 5 4.628082 -0.05314732 -1.0153053
## 6 3.983035 0.79696792 0.4444038You can also use high level functions from the factoextra package to extract relevant informations
## Eigenvalues
factoextra::get_eig(myPCA_ICL)## eigenvalue variance.percent cumulative.variance.percent
## Dim.1 493.9615 39.82669 39.82669
## Dim.2 287.6743 23.19435 63.02104
## Dim.3 214.6742 17.30857 80.32961
## Variables
factoextra::get_pca_var(myPCA_ICL)## Principal Component Analysis Results for variables
## ===================================================
## Name Description
## 1 "$coord" "Coordinates for the variables"
## 2 "$cor" "Correlations between variables and dimensions"
## 3 "$cos2" "Cos2 for the variables"
## 4 "$contrib" "contributions of the variables"
## Individuals
factoextra::get_pca_ind(myPCA_ICL)## Principal Component Analysis Results for individuals
## ===================================================
## Name Description
## 1 "$coord" "Coordinates for the individuals"
## 2 "$cos2" "Cos2 for the individuals"
## 3 "$contrib" "contributions of the individuals"And some of the very nice plotting methods such as biplots, correlation circles and scatter plots of the scores.
factoextra::fviz_pca_biplot(myPCA_ICL)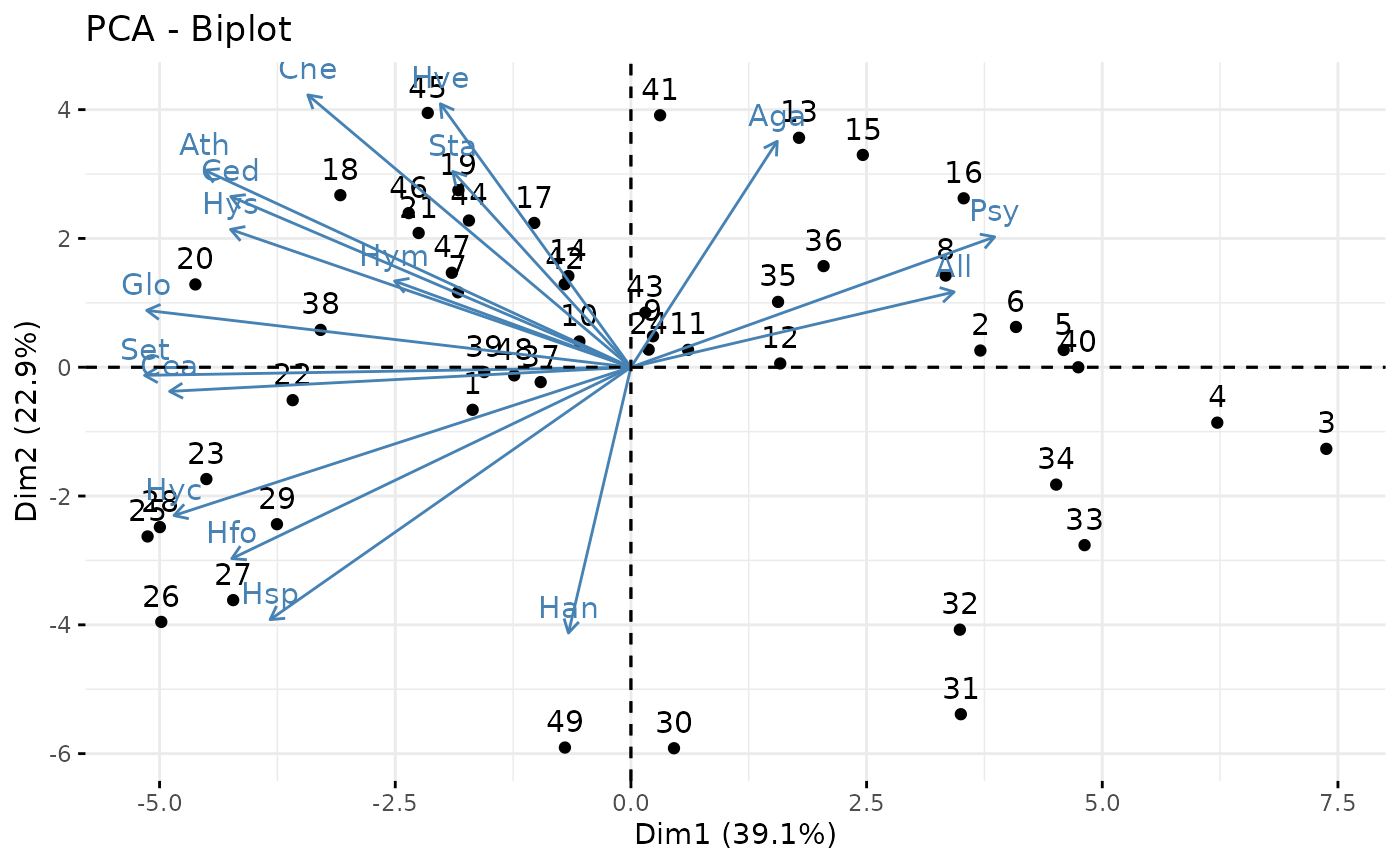
factoextra::fviz_pca_var(myPCA_ICL)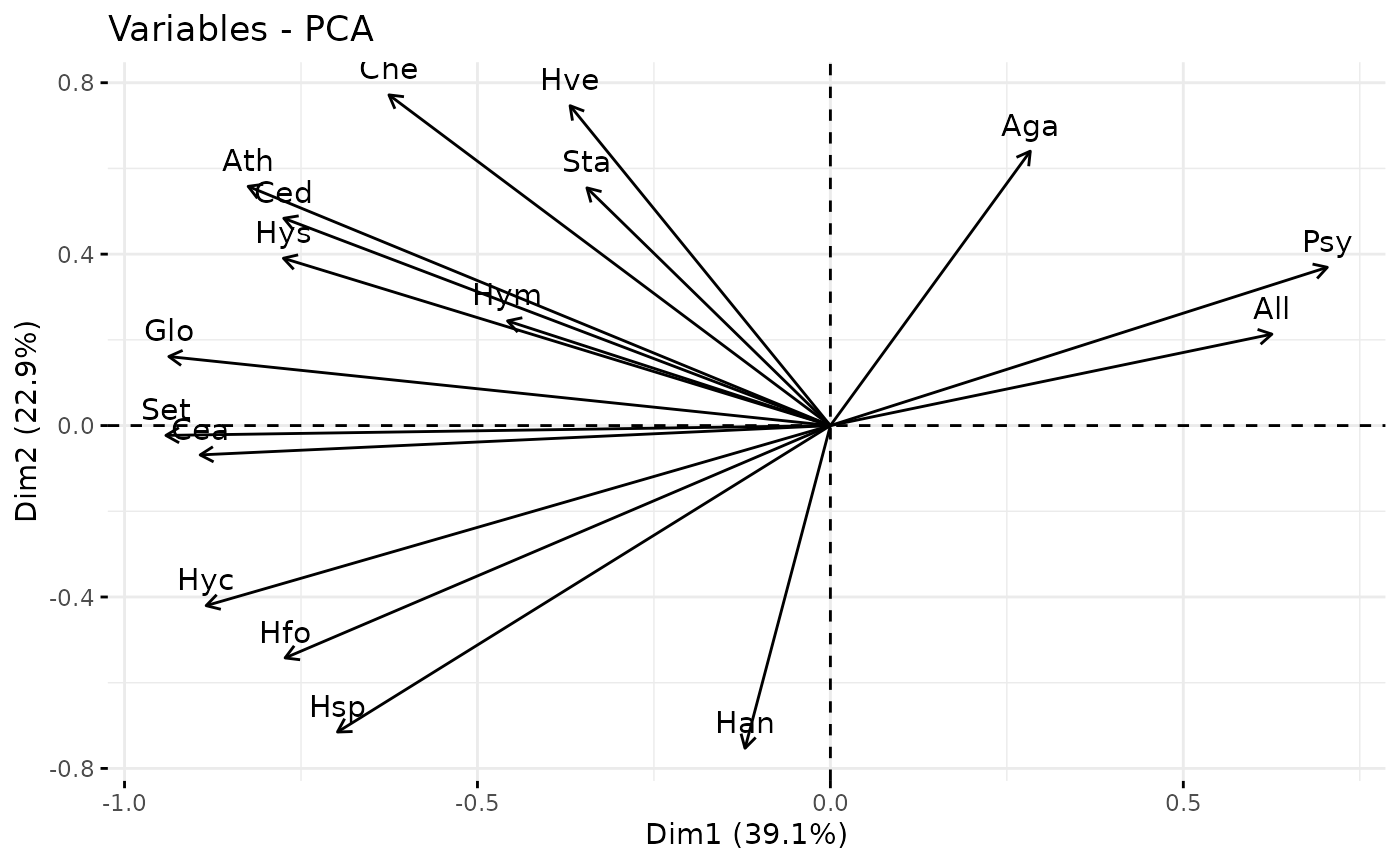
factoextra::fviz_pca_ind(myPCA_ICL)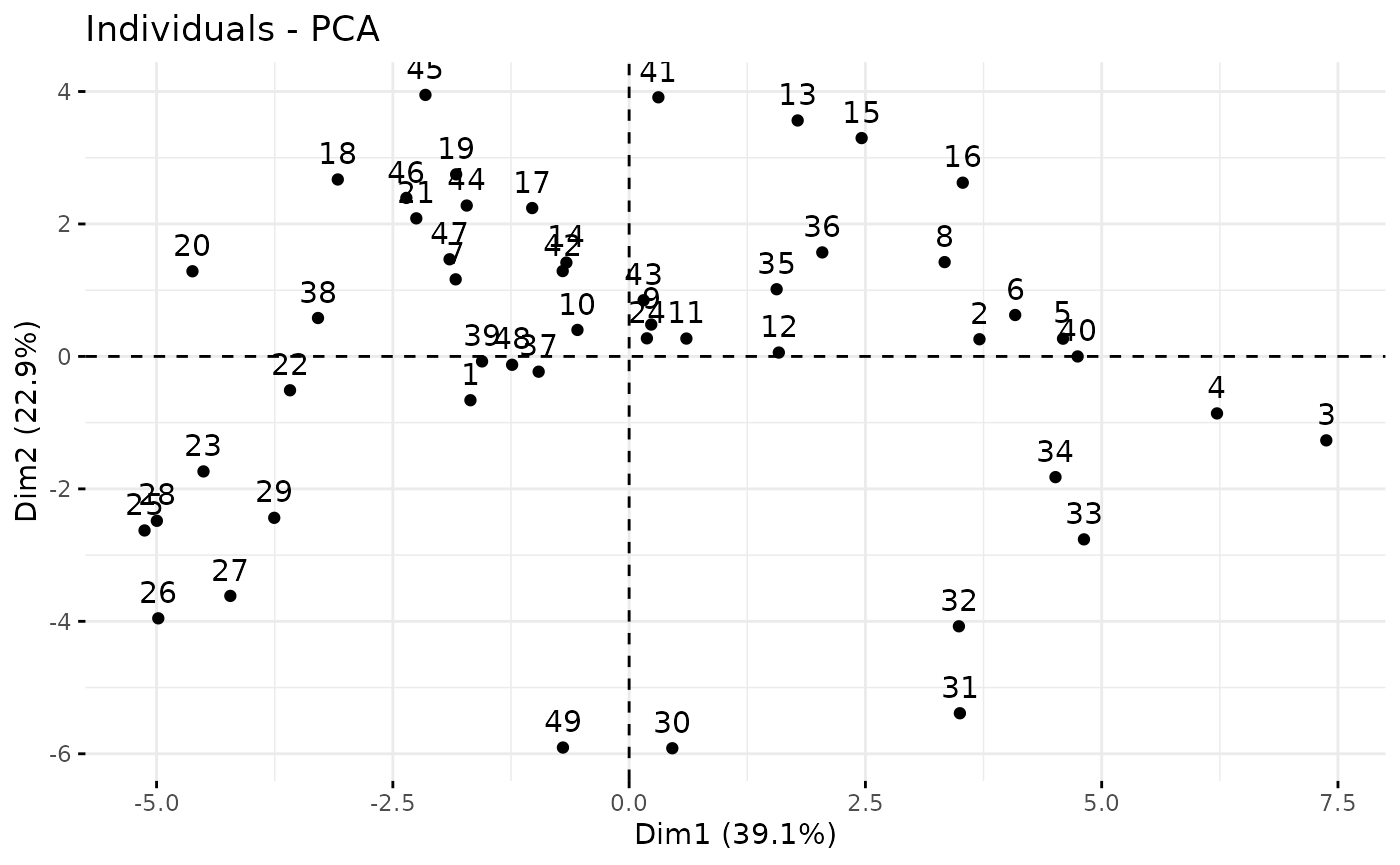
Projecting new data in the PCA space
You can project new data in the PCA space although it’s slightly involved at the moment. We demonstrate that by projecting the original data on top of the original graph. As expected, the projections of the new data points (small red points) are superimposed to the original data points (large black points).
## Project newdata into PCA space
new_scores <- myPCA_ICL$project(newdata = trichoptera)
## Overprint
p <- factoextra::fviz_pca_ind(myPCA_ICL, geom = "point", col.ind = "black")
factoextra::fviz_add(p, new_scores, geom = "point", color = "red",
addlabel = FALSE, pointsize = 0.5)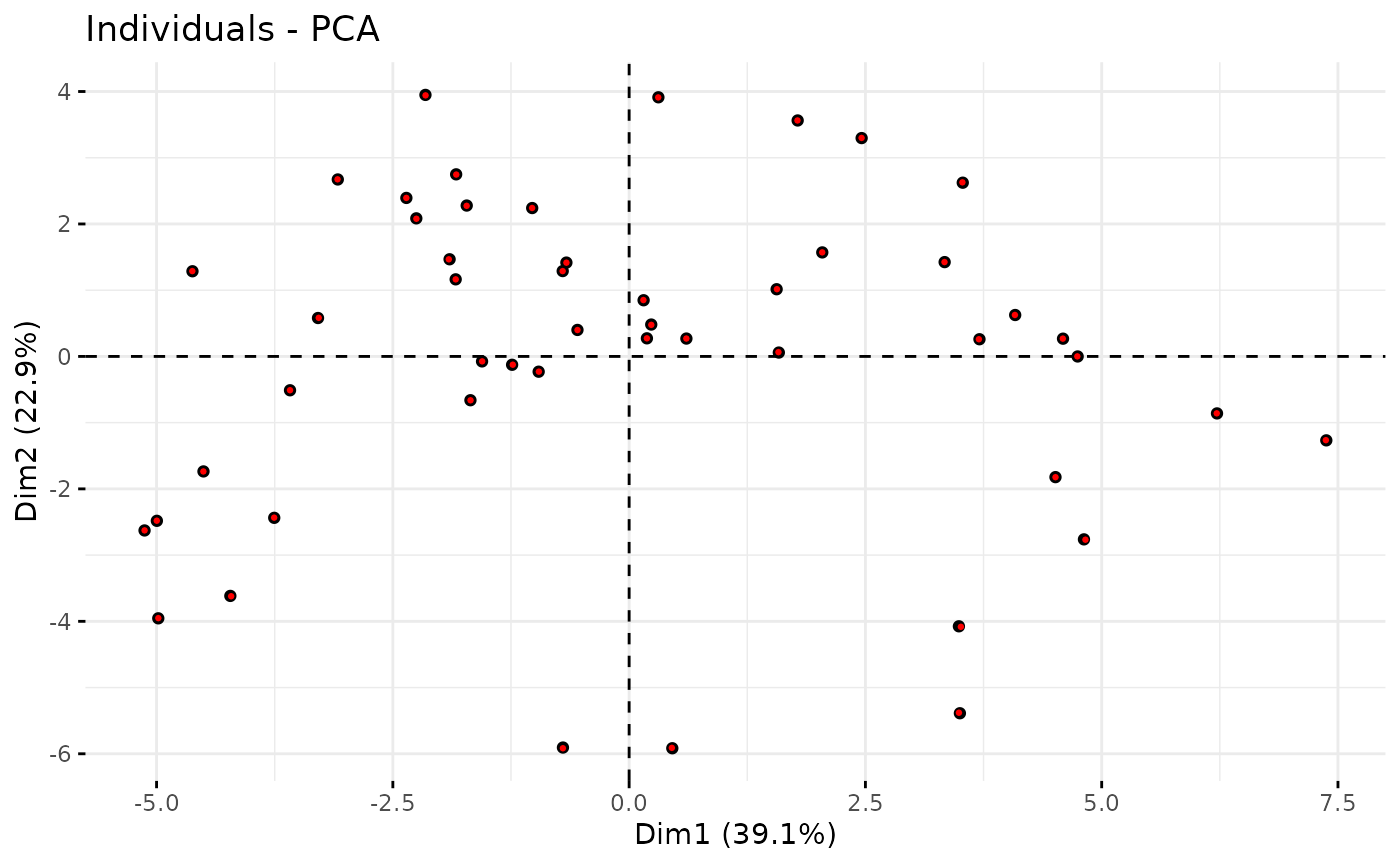
A model accounting for meteorological covariates
A contribution of PLN-PCA is to let the possibility to taking into account some covariates in the parameter space. Such a strategy often completely changes the interpretation of PCA. Indeed, the covariates are often responsible for some strong structure in the data. The effect of the covariates should be removed since they are often quite obvious for the analyst and may hide some more important and subtle effects.
In the case at hand, the covariates corresponds to the meteorological variables. Let us try to introduce some of them in our model, for instance, the temperature, the wind and the cloudiness. This can be done thanks to the model formula:
PCA_models_cov <-
PLNPCA(
Abundance ~ 1 + offset(log(Offset)) + Temperature + Wind + Cloudiness,
data = trichoptera,
ranks = 1:4
)##
## Initialization...
##
## Adjusting 4 PLN models for PCA analysis.
## Rank approximation = 1 Rank approximation = 2 Rank approximation = 3 Rank approximation = 4
## Post-treatments
## DONE!Again, the best model is obtained for classes.
plot(PCA_models_cov)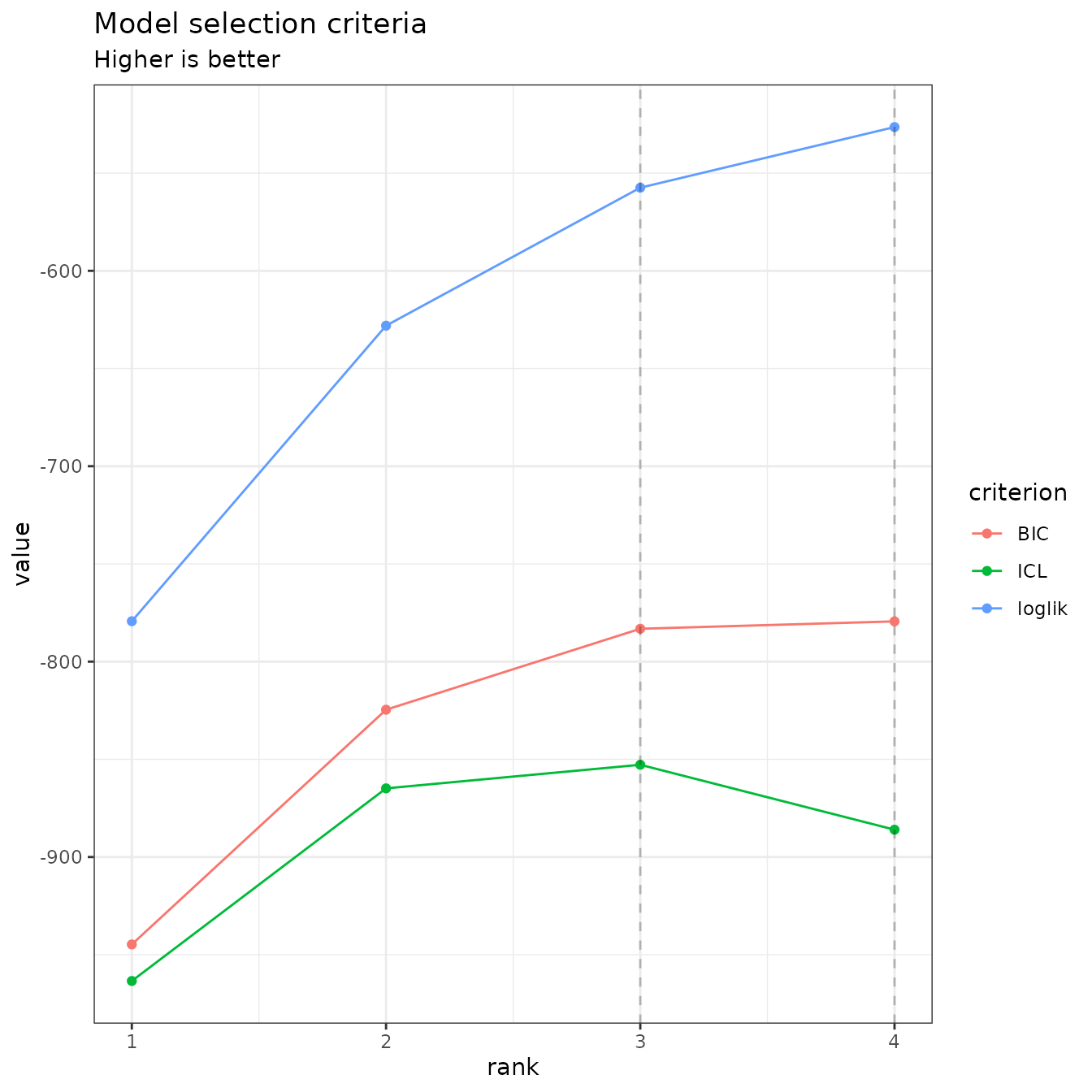
myPCA_cov <- getBestModel(PCA_models_cov, "ICL")Suppose that we want to have a closer look to the first two axes. This can be done thanks to the plot method:
gridExtra::grid.arrange(
plot(myPCA_cov, map = "individual", ind_cols = trichoptera$Group, plot = FALSE),
plot(myPCA_cov, map = "variable", plot = FALSE),
ncol = 2
)
We can check that the fitted value of the counts – even with this low-rank covariance matrix – are close to the observed ones:
data.frame(
fitted = as.vector(fitted(myPCA_cov)),
observed = as.vector(trichoptera$Abundance)
) %>%
ggplot(aes(x = observed, y = fitted)) +
geom_point(size = .5, alpha =.25 ) +
scale_x_log10(limits = c(1,1000)) +
scale_y_log10(limits = c(1,1000)) +
theme_bw() + annotation_logticks()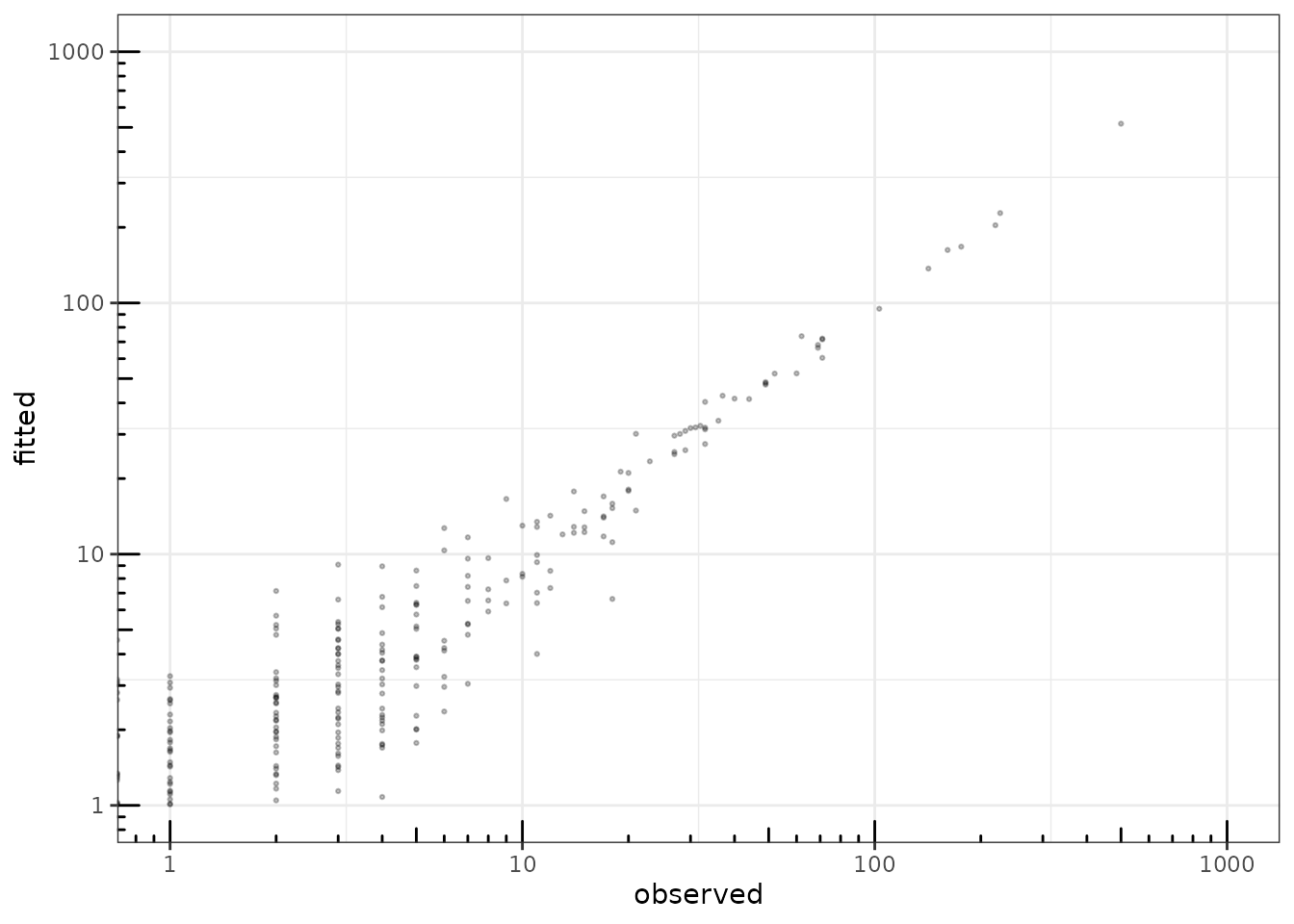
fitted value vs. observation
When you are done, do not forget to get back to the default (sequential) behavior.
options(mc.cores = 1)